정규화(Normalization)
관계형 데이터베이스(RDBMS)의 설계에서 데이터를 중복 없이 효율적으로 저장하기 위한 과정
정규화를 통해 데이터베이스 구조는 불필요한 중복을 최소화하고 데이터의 일관성과 무결성을 유지할 수 있게 된다.
정규화를 통해 DB는 이상 현상(Anomaly)를 방지할 수 있다.
이상 현상(Anomaly)
정규화를 적절히 하지 않은 DB 또는 Relation(Table)에 데이터가 중복되고 이 Table에 어떠한 작업을 할 때 비합리적인 문제들이 발생하는 현상이다.
- Relation : Rows(행)과 Columns(열)로 구성된 테이블
이상 현상 종류
- 삽입 이상 : 데이터를 테이블에 저장할 때, 불필요한 데이터도 넣어야 하는 경우
- 삭제 이상 : 데이터를 테이블에서 삭제할 때, 원하지 않는 데이터도 같이 삭제되는 경우
- 갱신 이상 : 중복된 데이터 중에서 특정 부분만 수정되어 값이 모순을 일으키는 경우
예제
예시 테이블
| 학번 | 학생 이름 | 담임 선생님 번호 | 담임 선생님 이름 |
| 1410015 | 콜드 | 34 | 마룬 |
| 1410020 | 플레이 | 63 | 파이브 |
삽입 이상
| 학번 | 학생 이름 | 담임 선생님 번호 | 담임 선생님 이름 |
| 1410015 | 콜드 | 34 | 마룬 |
| 1410020 | 플레이 | 63 | 파이브 |
| 1410025 | 마이클 | ? | ? |
- '1410025' 학번의 마이클 학생을 테이블에 넣으려고 하는데 담임 선생님이 없으면 입력할 수 없다.
삭제 이상
| 학번 | 학생 이름 | 담임 선생님 번호 | 담임 선생님 이름 |
| 1410015 | 콜드 | 34 | 마룬 |
- '파이브' 선생님이 이직을 하면, '플레이'라는 학생 정보도 삭제된다.
갱신 이상
| 학번 | 학생 이름 | 담임 선생님 번호 | 담임 선생님 이름 |
| 1410015 | 콜드 | 72 | 조니 |
| 1410020 | 플레이 | 63 | 파이브 |
- '콜드' 학생의 담임선생님을 변경할 때, (기존 선생님인) '마룬'의 정보가 없어진다.
단계별 정규화
| 단계 | 조건 |
| 1정규형(1NF) | 테이블 내의 속성 값들이 원자 값으로 구성 |
| 2정규형(2NF) | 부분함수 종속 제거 |
| 3정규형(3NF) | 이행함수 종속 제거 |
| 보이스-코드 정규형 (BCNF) |
결정자 함수이면서 후보 키가 아닌 것 제거 |
| 4정규화(4NF) | 다치(다중 값) 중속성 제거 |
| 5정규형(5NF) | 조인 종속성 제거 |
1차 정규화(1NF) - 원자값으로 구성
- 테이블의 모든 열(Rows)에는 원자 값만 포함되어야 한다(각 열에는 중복되지 않는 단일 값만 있어야 한다).

첫 번째 테이블은 한 user에게 email 주소가 두 개 들어가 있다.
이는 원자 값으로 구성되어 있지 않은 것으로 유저가 하나의 email 주소를 변경했을 대, 기존 email 값에서 변경된 값을 다시 찾아서 다시 넣어줘야 한다거나, 다 가져와서 변경된 걸 찾아넣고 모두 덮어쓰기를 한다거나의 문제가 있을 수 있다(중복 값이 들어갈 수도 있다).
아래 테이블처럼 나눠줘야 email을 원자 값으로 구성했다고 할 수 있으며, 1차 정규화를 만족하는 것이다.
2차 정규화(2NF) - 부분함수 종속 제거
- 부분적 종속성을 제거하는 데 초점을 맞춘다.
- 부분적 종속성: 기본 키가 아닌 부분 집합의 열이 기본 키에 종속되는 경우, 이를 해결하기 위해 테이블을 적절히 분리해서 각 테이블이 한 개의 주제에 집중하게 해야 한다.

위 테이블을 보면 UserName과 Sports가 Term과 연관되어 있다. UserName은 여러 개 있을 수도 있고, Sports도 여러 개 있을 수 있으므로 둘이 묶여야 Term이 정해진다.
Sports가 Prices와 연관이 있으므로 UserName, Sports - Term | Sports - Prices를 보면 Sports가 부분적으로 관계가 있으며, 이를 부분함수 종속 관계라고 한다.

부분적으로 연관되어 있는 두 값을 나누는 것이 2차 정규화로, 부분함수 관계를 끊어서 아래 테이블이 된 것이 2차 정규화가 된 것이다.
3차 정규화(3NF) - 이행함수 종속 제거
- 이행적 종속성을 제거하는 데 초점을 맞춘다.
- 이행적 종속성: A → B, B → C의 관계에서 A → C의 관계가 성립되는 경우를 말하며, 이를 해결하기 위해 중복을 피하고 각 테이블이 독립적으로 유지되도록 한다.
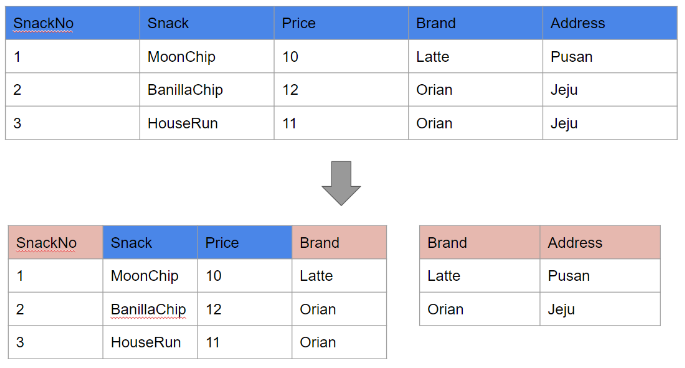
위 테이블의 SnackNo이 Brand와 연관이 있고 Brand가 Address로 연관되어 있어 이행함수 관계이다.

Snack의 생산 Brand가 바뀌는 경우가 있다면, 해당 Address도 바꿔줘야하는 갱신 이상이 발생할 수 있으므로 이를 나누는 것으로 3차 정규화를 만족시켜야 한다.
보이스-코드 정규화(BCNF : Boyce-Codd NF) - 결정자 함수이면서 후보 키가 아닌 것을 제거
- 모든 결정자가 후보 키인 상태
- 3차 정규화를 진행한 테이블에 대해 모든 결정자가 후보 키가 되도록 테이블을 분해하는 것.
- 3차 정규화를 더욱 강화한 개념으로, 3차 정규화에서 발생하는 일부 문제를 해결한다.
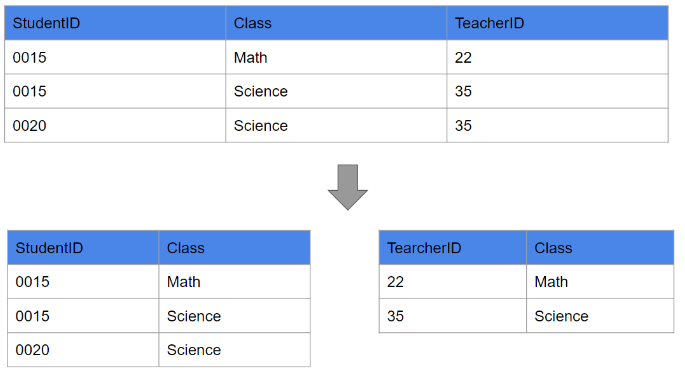
보이스-코드 정규화는 3차 정규화와 매우 비슷해 3.5차 정규화라고도 한다.
위 테이블의 학생 번호와 과목을 하나의 기본 키로 본다면, 이를 통해 선생님을 식별할 수 있다.
그런데 선생님은 과목과 연관되어 있는데, 이는 선생님을 통해 과목을 결정할 수 있으므로 선생님을 결정자라고 할 수 있다.
선생님은 테이블에서 중복될 수 있어, 결정자이지만 중복이 가능해서 키로써 역할을 할 수 없다(후보 키가 될 수 없다).

영어를 가르치는 새로운 선생님이 들어올 경우, row를 추가해 줘야하는데, 해당 과목을 듣는 학생이 없으면 학생은 null 값이 된다.
학생은 기본 키이므로 null 값이 들어갈 수 없어서 문제가 발생하게 되므로, 아래 테이블처럼 나눠야 이상 현상을 막을 수 있다.
- 보통 BCNF 까지 진행을 했다면, 이후 정규화에 대해선 만족을 한다고 한다. 그러니 여기까지만 진행해도 Table에 큰 문제 없을 것이라고 본다.
4차 겅규화(4NF) - 다치(다중 값) 종속 제거
- 다치 종속을 제거하는 데 초첨을 맞춘다.
- 다치(다중값) : 값이 여러 개인 것.

위 테이블은 개발자가 많은 자격증을 가질 수도 있고, 많은 언어를 사용할 수도 있는데, 자격증과 언어를 합쳐 놓을 경우 이상 현상이 발생할 수 있다.
개발자가 새로운 자격증을 취득해서 row을 추가하려면, 언어 column에도 어떠한 값이든 추가해 줘야하고, 개발자의 자격증이 만료되어 삭제하려고 하면, 개발자의 언어도 같이 삭제되어 데이터 관리가 제대로 되지 않게 된다.
그래서 개발자를 기준으로 중복된 값을 허용할 수 있게 나눠야 4차 정규화를 만족시킬 수 있다.

5차 정규화(5NF) - 조인 종속성 제거
- 조인 종속성을 제거하는 데 초점을 맞춘다.
- 조인 종속성 : 4차 정규화 된 테이블을 Join 했을 때, 정규화 이전의 table과 값이 달라지는 경우를 조인 종속성을 가졌다고 한다(Join 또는 정규화 과정에서 데이터가 손실되어 결과가 달라지는 것).

Join 했을 때 정상적으로 유지될 수 있도록 모든 속성 관계에 대한 테이블을 만들어서 Join 시 원래의 데이터가 나올 수 있도록 하는 것을 5차 정규화라고 한다.


정규화의 원칙
- 정보의 무손실 표현 : 하나의 Schema를 다른 Schema로 변환할 때 정보의 손실이 없어야 한다.
- 분리의 원칙 : 하나의 독립된 관계성은 하나의 독립된 Relation으로 분리시켜 표현해야 한다.
- 데이터의 중복성이 감소되어야 한다.
정규화의 장단점
정규화의 장점
- 데이터베이스 변경 시 이상 현상(Anomaly)을 제거할 수 있다.
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다(데이터 삽입 시 Relation 재구성의 필요성 감소).
- 데이터베이스와 연동된 응용 프로그램에 최소환의 영향만을 미치게 되어 응용프로그램의 생명을 연장시킨다.
- 효과적인 검색 알고리즘 생성 가능
- 데이터 구조의 안정성 및 무결성 유지
정규화의 단점
- Relation 분해로 인한 Relation 간의 Join 연산이 많아지므로, 응답 시간이 느려질 수도 있다.
- 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 용량이 최소화 되어 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있다.
조인이 많이 발생하여 성능 저하가 나나나면 반정규화(De-normalization)를 적용할 수도 있다.
비정규화(De-normalization, 반정규화)
하나 이상의 테이블에 데이터를 중복해 배치하는 최적화 기법
시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로, 의도적으로 정규화 원칙을 위해하는 행위
정규화로 인한 테이블의 분리되는데, 테이블의 규모가 클 경우 Join으로 불필요할 정도로 많은 시간을 낭비하게 된다.
비정규화는 이러한 문제를 해결하기 위해 어느 정도의 데이터 중복이나 그로 인해 발생하는 데이터 갱신 비용을 감수하는 대신 조인 횟수를 줄여 한층 효율적인 쿼리를 날릴 수 있도록 하는 것이다.
장점
- 빠른 데이터 조회 : Join이 줄어들기 때문
- 확인할 테이블이 줄어들기 때문에 데이터 조회 쿼리가 간단 해짐 : 버그 발생 가능성도 줄어든다.
단점
- 데이터 갱신이나 삽입 비용이 높다.
- 데이터 갱신 또는 삽입 코드를 작성하기 어려워 진다.
- 데이터 간의 일관성이 깨질 수 있다.
- 데이터를 중복하여 저장하므로 더 많은 저장 공간이 필요하다.
비정규화 대상
- 자주 사용되는 테이블에 액세스하는 프로세스의 수가 가장 많고, 항상 일정한 범위만을 조회하는 경우
- 테이블에 대량 데이터가 있고 대량의 범위를 자주 처리하는 경우, 성능 상 이슈가 있을 경우
- 테이블에 지나치게 조인을 많이 사용하게 되어 데이터를 조회하는 것이 기술적으로 어려울 경우
대규모 IT 업체의 경우처럼, 규모 확장성(scalability)을 요구하는 시스템의 경우 항상 정규화된 데이터베이스와 비정규화된 데이터베이스를 섞어 사용한다.
주의점
- 반정규화를 과도하게 적용하다 보면 데이터의 무결성이 깨질 수 있다.
- 입력, 수정, 삭제 질의문에 대한 응답 시간이 늦어질 수도 있다.
'항해 99' 카테고리의 다른 글
| 멀티 프로세스 & 멀티 스레드 (1) | 2024.04.26 |
|---|---|
| 프로세스, 스레드 (0) | 2024.04.25 |
| WIL-11 (1) | 2024.04.21 |
| 기술면접 준비 3주차 정리 (1) | 2024.04.18 |
| NoSQL & RDBMS (0) | 2024.04.17 |

