개요
애플리케이션을 운영하기 위해서는 지속적인 상태 확인을 위한 모니터링이 필요하고 모니터링에서 발견한 장애(문제)를 해결하는 것도 중요하다.
그렇기 때문에 애플리케이션에서 발생할 수 있는 장애와 그 대응 방법에 대해 정리해 볼 것이다.
장애 대응?
시스템에서 문제가 발생했을 때 빠르고 효율적으로 대응하여 서비스 중단을 최소화하는 데 초점이 맞춰져 있다.
Java/Spring 기반 시스템 장애 대응 방법
1. 예방 단계
- 로깅과 모니터링
- 로깅: Spring Boot Actuator와 같은 라이브러리를 활용해 시스템 로그를 기록, Logback 또는 SLF4J와 같은 로깅 프레임워크를 사용하여 정보를 출력
- 모니터링
- Prometheus와 Grafan로 시스템 상태를 시각화한다.
- Spring Boot Actuator를 활용하여 애플리케이션의 메트릭(메모리, CPU 사용량, 스레드 상태 등)을 수집한다.
- 헬스 체크(Health Check)
- Actuator의 /actuator/health 엔드포인트를 통해 시스템의 상태를 확인한다.
- 예를 들어, 데이터베이스 연결 상태, 외부 API 의존성 등을 실시간으로 확인할 수 있다.
- 회귀 테스트와 CI/CD
- 장애 예방을 위해 철저한 테스트를 진행한다.
- Jenkins, GitHub Actions와 같은 CI/CD 도구를 활용하여 코드 배포 전 자동 테스트를 수행한다.
2. 대응 단계
- 장애 감지
- 알림 시스템: Spring Boot Actuator와 AlertManager를 결합하여 장애 발생 시 즉각적으로 알림을 보낸다(예: Slack, E-mail, SMS)
- 로그 분석: 장애 시 로그를 빠르게 확인할 수 있도록 ELK Stack(Elasticsearch, Logstash, Kibana) 같은 도구를 설정한다.
- 장애 격리
- Circuit Breaker 패턴: Resilience4j 또는 Spring Cloud Circuit Breaker를 활용하여 특정 서비스의 실패가 전체 시스템에 영향을 주지 않도록 한다.
- 예: 외부 API 호출이 실패하면 대체 응답을 반환하거나 호출을 차단
- Rate Limiting: Bucket4j 또는 Spring Cloud Gateway를 통해 과도한 요청을 제한하여 시스템이 과부화되지 않도록 한다.
- Circuit Breaker 패턴: Resilience4j 또는 Spring Cloud Circuit Breaker를 활용하여 특정 서비스의 실패가 전체 시스템에 영향을 주지 않도록 한다.
- 장애 처리
- Fallback: 주요 서비스가 실패했을 때 대체 로직을 실행하도록 구현한다.
- 예: 데이터베이스 연결 실패 시 캐시 데이터를 반환
- Retry Mechanism: Spring Retry를 사용해 특정 작업이 실패할 경우 재시도를 구현한다.
- Fallback: 주요 서비스가 실패했을 때 대체 로직을 실행하도록 구현한다.
3. 복구 단계
- 롤백
- 장애가 발생한 경우, Transactional과 같은 Spring의 트랜잭션 관리 기능을 활용하여 작업을 롤백한다.
- 배포와 관련된 장애라면 Blue-Green Deployment 또는 Canary Release를 통해 안정적인 버전으로 롤백한다.
- 데이터 복구
- 정기적으로 백업을 수행하여 장애 시 데이터를 복구할 수 있도록 한다.
- PostgreSQL이나 MySQL의 복제 기능을 활용하여 복구 시간을 단축한다.
- 장애 분석 및 개선
- 장애 발생 후 Post-Mortem 회의를 통해 문제 원인을 분석하고 향후 유사한 문제가 발생하지 않도록 방안을 마련합니다.
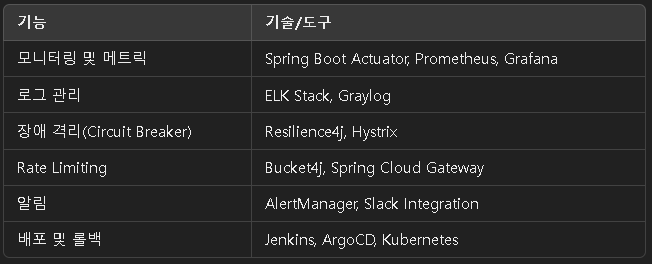
4. 자주 사용되는 기술 스택
5. 예시 코드
Circuit Breaker 설정(Resilience4j)
@CircuitBreaker(name = "exampleService", fallbackMethod = "fallbackResponse")
public String callExternalService() {
// 외부 API 호출
return restTemplate.getForObject("http://external-service/api", String.class);
}
public String fallbackResponse(Throwable t) {
// 장애 시 반환할 기본 응답
return "Default Response";
}
Health Check 설정(Spring Boot Actuator)
management:
endpoints:
web:
exposure:
include: health, metrics
장애 대응의 핵심
- 사전 예방, 실시간 감지, 신속한 복구
Failover
Failover는 장애 대응의 대응 단계와 복구 단계에 모두 걸쳐 있는 중요한 기술.
시스템이 장애를 감지했을 때, 서비스 중단을 최소화하기 위해 자동 또는 수동으로 백업 시스템이나 대체 리소스로 전환하는 과정
1. Failover의 위치
대응 단계: 장애 감지 후 즉시 대응
- 장애 격리와 전환:
- 주요 노드(서버, 데이터베이스 등)에서 장애가 발생하면 다른 노드로 트래픽을 전환한다.
- 예: 데이터베이스 장애 발생 시, 복제된 데이터베이스(Primary → Replica)로 자동 전환.
복구 단계: 정상화 후 안정적인 상태 유지
- Failback(복구 전환):
- 장애가 복구된 후, 다시 원래의 주요 리소스로 전환하여 기존 시스템의 성능과 기능을 복원한다.
- 예: 장애가 해결된 Primary DB로 다시 전환.
2. Failover의 유형
- 하드웨어 또는 서버 장애 대응:
- 로드 밸런서를 통해 특정 서버 장애 시 다른 서버로 트래픽을 자동 분산.
- 예: AWS ELB(Elastic Load Balancer), NGINX Reverse Proxy.
- 데이터베이스 장애 대응:
- Master-Slave Replication:
- Master DB가 장애를 일으키면 Slave DB로 자동 전환.
- Cluster 관리:
- PostgreSQL의 Patroni 또는 MySQL의 MHA(Master High Availability)를 활용.
- Master-Slave Replication:
- 네트워크 장애 대응:
- DNS 레벨에서 장애 발생 시, 대체 IP나 다른 지역의 데이터 센터로 트래픽을 리디렉션.
- 예: AWS Route 53의 DNS Failover 기능.
3. Failover 설정 예시
데이터베이스의 Master-Slave Failover 설정(PostgreSQL + Patroni)
- 구성: Primary DB에서 장애 발생 시, Secondary DB로 자동 전환
scope: my-cluster
namespace: /service/
name: postgresql-01
restapi:
listen: 127.0.0.1:8008
connect_address: 192.168.1.1:8008
etcd:
host: 192.168.1.2:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
initdb:
- encoding: UTF8
- data-checksums
- Spring Boot에서 DB 연결(Failover 지원)
spring:
datasource:
url: jdbc:postgresql://primary-db:5432,replica-db:5432/mydb?targetServerType=primary
username: user
password: pass
hikari:
fail-fast: true
4. Failover의 장단점
- 장점
- 서비스 지속성: 장애 상황에서도 사용자 경험에 큰 영향을 주지 않음.
- 복구 시간 단축: 자동 전환으로 MTTR(평균 복구 시간)을 줄임.
- 단점
- 설정 복잡성: 초기 설정 및 유지보수 비용 증가.
- 일관성 문제: 데이터 동기화 지연으로 인해 일관성 문제가 발생할 수 있음.
5. Failover 활용을 위한 모니터링
- 장애 감지를 위해 항상 모니터링 시스템과 연계해야 함.
- 예: Prometheus로 장애 탐지 후 Failover 트리거.
- 트리거 실패 시 수동 전환을 위한 절차를 마련.
Failover는 대응 단계에서 즉각적인 장애 전환을 수행하고, 복구 단계에서 안정화된 상태로 복귀하기 위한 중요한 기술.
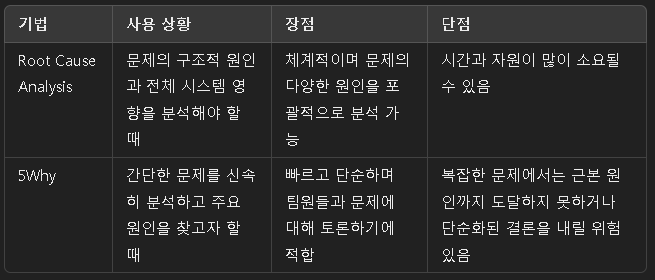
Root Cause Analysis, 5Why
장애 원인 분석(Root Cause Analysis, RCA)와 5Why 기법은 장애의 근본적인 원인을 식별하고 반복적으로 발생하지 않도록 방지하기 위해 사용하는 방법론.
장애 대응의 복구 단계에서 주로 활용되며, RCA는 전체적인 방법론이고 5Why는 RCA의 한 기법.
1. Root Cause Analysis(RCA)
정의
- 문제가 발생한 근본적인 원인(Root Cause)을 식별하여, 문제를 재발하지 않도록 근본적으로 해결하는 프로세스.
주요 목표
- 장애의 표면적 증상이 아닌 근본 원인을 찾는다.
- 유사한 문제가 다시 발생하지 않도록 예방 조치를 마련한다.
- 문제를 체계적으로 분석하여 프로세스를 개선한다.
RCA의 단계
- 문제 정의
- 발생한 장애의 영향을 명확히 규정.
- 예: DB 연결 실패로 서비스가 중단됨.
- 데이터 수집
- 로그, 시스템 메트릭, 사용자 보고서 등을 통해 문제 발생 시점의 정보를 수집.
- 도구: ELK Stack, Prometheus, Datadog.
- 원인 분석
- 도구와 기법을 사용해 근본 원인을 분석.
- 5Why 기법, Fishbone Diagram, Fault Tree Analysis.
- 해결 방안 수립
- 근본 원인에 맞는 조치를 설계.
- 예: 서버 스케일링 자동화, 트래픽 분산 설정.
- 예방 조치 실행
- 문제 재발 방지를 위한 개선 작업을 수행.
장점
- 문제 해결의 정확성을 높이고, 반복적인 장애를 방지.
- 문제 발생 프로세스를 체계적으로 이해.
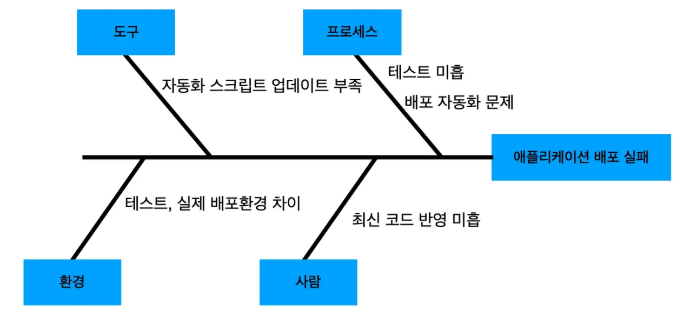
2. 5Why 기법
5Why는 한 문제에 대해 왜(Why)? 라는 질문을 반복하여 근본 원인에 도달하는 분석 기법.
일반적으로 5번 정도 반복하지만, 상황에 따라 더 적거나 많은 단계가 필요할 수도 있다.
예시
문제: 서버 CPU 사용량 급증으로 서비스 중단 발생
- 왜(Why)? 서버 CPU가 한계치에 도달했는가?
- 과도한 트래픽이 유입됨.
- 왜(Why)? 과도한 트래픽이 유입되었는가?
- 특정 시간대에 배치 작업과 사용자 요청이 동시에 처리됨.
- 왜(Why)? 배치 작업이 사용자 요청과 동시에 처리되었는가?
- 배치 작업이 비효율적으로 설계되어 사용자 요청과 자원을 공유함.
- 왜(Why)? 배치 작업이 비효율적으로 설계되었는가?
- 초기 설계 시 예상 부하를 충분히 고려하지 않음.
- 왜(Why)? 예상 부하를 충분히 고려하지 않았는가?
- 시스템 설계 단계에서 부하 테스트가 누락됨.
결론
근본 원인은 부하 테스트 미흡이며, 개선 조치로 부하 테스트 도입 및 설계 개선을 수행.
3. RCA와 5Why의 활용
4. Java/Spring 기반 사례
RCA 예시
- 문제: 서비스가 간헐적으로 다운됨.
- 수집된 데이터:
- 장애 발생 시점의 로그: DB Connection Pool 초과.
- 메트릭: 트래픽 급증, 메모리 사용량 증가.
- 장애 상황 재현 테스트 결과: Connection Pool 임계치 도달.
- 근본 원인: 비효율적인 DB 쿼리로 인해 연결이 장시간 점유됨.
- 해결 방안:
- 쿼리 최적화.
- Connection Pool 크기 조정.
- Redis 캐시를 활용한 DB 부하 감소.
5Why 기법 예시
- 문제: 특정 API 호출이 실패.
- 왜? API 호출 시 타임아웃 발생.
- 왜? 외부 서비스 응답 시간이 길어짐.
- 왜? 외부 서비스의 로드 밸런싱 문제.
- 왜? 외부 서비스 설정이 잘못됨.
- 왜? 외부 서비스 운영 팀과의 커뮤니케이션 누락.
- 결론: 외부 서비스 설정 및 SLA(Support Level Agreement) 재확인 필요
5. 도구
- RCA 지원 도구
- ELK Stack: 장애 데이터 분석.
- Prometheus & Grafana: 메트릭 기반 원인 파악.
- 팀 협업
- Confluence, Jira: 분석 결과 문서화 및 개선 작업 관리.
- Miro: Fishbone Diagram 작성.
장애 예방 전략 및 예방 조치
장애 예방 전략과 예바 조치는 장애가 발생하기 전 미리 시스템의 안정성과 신뢰성을 강화하여 문제를 방지하는 데 중점을 둔다.
예방 전략은 장기적이고 전체적인 계획에 해당하며, 예방 조치는 구체적인 실행 단계를 의미.
1. 장애 예방 전략
1.1 시스템 설계 단계에서 예방
- 고가용성(High Availability) 설계
- 장애 발생 시 서비스를 지속적으로 제공할 수 있도록 다중화된 아키텍처 구축.
- 예: 이중화된 데이터베이스, 애플리케이션 서버 클러스터링.
- 분산 아키텍처
- 시스템을 분리하여 장애가 특정 컴포넌트에 국한되도록 설계.
- 예: 마이크로서비스 아키텍처(MSA).
- 확장성 설계
- 트래픽 증가에 따라 리소스를 유연하게 확장.
- 예: Auto Scaling, Kubernetes 기반의 컨테이너 오케스트레이션.
- 장애 격리
- 장애가 발생했을 때 다른 컴포넌트로 전파되지 않도록 격리.
- 예: Circuit Breaker 패턴(Hystrix, Resilience4j).
1.2 운영 단계에서 예방
- 모니터링 및 알림 시스템
- 실시간 모니터링 도구를 통해 이상 징후를 조기에 탐지.
- 도구: Prometheus, Grafana, ELK Stack, Datadog.
- 성능 테스트
- 부하 테스트, 스트레스 테스트, 용량 계획을 통해 시스템 한계를 사전에 파악.
- 도구: JMeter, Gatling.
- 변경 관리(Change Management)
- 시스템 변경(코드 배포, 설정 변경) 시, 단계적으로 진행하여 리스크를 줄임.
- 예: Blue-Green Deployment, Canary Release.
- 로그 분석 및 장애 패턴 학습
- 과거 장애 로그와 데이터를 분석해 유사한 문제가 재발하지 않도록 조치.
- 예: 로그 정규화를 통해 자동 경고 시스템 구축.
- 백업 및 복구 체계
- 데이터 손실이나 시스템 장애에 대비해 정기적으로 백업.
- 예: Amazon RDS 스냅샷, PostgreSQL WAL(Write-Ahead Logging).
1.3 조직적인 예방
- 장애 대응 훈련
- 실제 장애 상황을 가정한 모의 훈련(Chaos Engineering).
- 도구: Gremlin, Chaos Monkey.
- 개발/운영 문화 개선
- DevOps 문화 도입: 개발과 운영 간의 협업 강화를 통해 실수를 최소화.
- CI/CD 파이프라인 구축으로 코드 품질 및 배포 자동화.
- 운영 프로세스 표준화
- 장애 발생 시 대응 절차(SOP, Standard Operating Procedure)를 문서화하고 팀에 공유.
2. 장애 예방 조치
2.1 코드 수준의 예방
- 코드 품질 강화
- 코드 리뷰, 정적 분석 도구 사용(SonarQube, Checkstyle).
- 예외 처리 강화
- 예상 가능한 모든 에러를 처리하고 시스템 다운을 방지.
-
try { externalService.call(); } catch (TimeoutException e) { // 타임아웃 예외 처리 fallbackMethod(); }
- 테스트 자동화
- 유닛 테스트, 통합 테스트, 회귀 테스트로 버그를 사전에 차단.
- 도구: JUnit, Mockito, Selenium.
2.2 환경 설정 및 구성
- 설정 관리
- 설정 파일과 코드를 분리하고 외부에서 관리.
- 도구: Spring Cloud Config, HashiCorp Vault.
- 환경 분리
- 개발, 테스트, 운영 환경을 물리적으로 또는 논리적으로 분리.
- 예: Docker로 각 환경별 컨테이너 관리.
2.3 시스템 안정성 강화
- 캐싱
- DB 부하를 줄이기 위해 자주 사용되는 데이터를 캐싱.
- 도구: Redis, Memcached.
- 데이터베이스 이중화
- Primary-Replica 구성을 통해 장애 발생 시 자동 Failover.
- 도구: PostgreSQL Patroni, MySQL MHA.
- 비동기 처리
- 대규모 요청 처리 시 비동기 메커니즘을 사용.
- 예: RabbitMQ, Kafka.
3. 장애 예방 사례
사례 1: 대규모 트래픽 장애 예방
- 문제: 이벤트 중 트래픽 급증으로 서버 다운.
- 예방 조치:
- 트래픽 분산을 위해 CDN 도입.
- Auto Scaling으로 인프라 자동 확장.
- Redis 캐싱으로 DB 요청 수 감소.
사례 2: 데이터 손실 예방
- 문제: DB 서버 장애로 데이터 유실.
- 예방 조치:
- RPO(Recovery Point Objective) 0을 목표로 지속적인 데이터 복제.
- 정기적인 백업 및 복구 테스트 수행.
4. 장애 예방의 핵심 원칙
- 문제는 사전에 발견하라
- 모든 장애는 사전에 예측 가능한 시그널을 보인다. 모니터링과 자동화 도구로 미리 탐지.
- 단순함을 유지하라
- 복잡한 시스템은 장애 발생 가능성을 높인다. 단순하고 명확한 아키텍처를 유지.
- 지속적으로 개선하라
- 장애가 발생했더라도 RCA를 통해 원인을 분석하고 시스템을 꾸준히 개선.
장애 대응에서 알아두면 좋은 추가 개념
1. SLA, SLO, SLI
- SLA (Service Level Agreement): 서비스 제공자와 사용자 간의 약속으로, 서비스의 가용성과 성능 수준을 정의.
- 예: "가용성 99.9% 보장."
- SLO (Service Level Objective): SLA를 달성하기 위한 내부 목표.
- 예: "응답 시간 1초 이내 95% 유지."
- SLI (Service Level Indicator): SLO의 실제 성과를 측정하는 지표.
- 예: "지난 1시간 동안 응답 시간이 1초 이하였던 비율."
활용 방법: SLA/SLO/SLI를 정의하고 모니터링하여 장애 발생 시 비즈니스에 미치는 영향을 파악.
2. MTTR, MTBF
- MTTR (Mean Time to Repair): 장애가 발생했을 때 복구하는 데 걸리는 평균 시간.
- MTBF (Mean Time Between Failures): 장애 간의 평균 간격.
활용 방법: MTTR을 단축하기 위해 복구 프로세스를 개선하고, MTBF를 늘리기 위해 예방 조치를 강화.
3. Postmortem 작성
- 장애가 발생한 후, 문제 원인과 대응 과정을 문서화하여 팀과 공유.
- 포함 내용:
- 장애 발생 시간 및 영향 범위.
- 원인 및 복구 단계.
- 예방 조치 및 교훈.
- 예: Google의 SRE 팀은 Postmortem을 통해 유사한 장애를 방지하고 시스템을 개선.
- 포함 내용:
Best Practice: Postmortem 작성 시 비난하지 않는 문화를 조성하여 팀원들이 문제를 솔직히 공유하도록 유도.
4. 신뢰성 엔지니어링 (SRE, Site Reliability Engineering)
- 개념: Google에서 시작된 운영 철학으로, 소프트웨어 엔지니어링 원칙을 적용해 서비스의 신뢰성을 유지.
- 핵심 활동:
- 자동화 도구 개발로 장애 대응 속도 향상.
- 서비스 신뢰성(SLO)을 기준으로 시스템 운영.
활용 사례: 시스템의 신뢰성을 높이기 위해 DevOps와 함께 SRE 팀을 구성.
장애 대응에서 알아두면 좋은 추가 실천 사항
1. 장애 대응 프로세스 표준화
- 장애 인식 단계
- 실시간 모니터링 및 알림 시스템을 통해 장애 발생을 즉시 인지.
- 예: PagerDuty, Opsgenie를 사용한 알림 설정.
- 장애 대응 단계
- 장애의 심각도를 판단하고 우선순위에 따라 대응.
- 장애 심각도(S1, S2, S3) 기준을 정의:
- S1: 모든 사용자 영향 (즉시 대응 필요).
- S2: 일부 사용자 영향 (일정 내 복구).
- S3: 사용자 경험 저하 없음 (모니터링 후 대응).
- 복구 및 분석 단계
- 장애를 복구한 후 RCA와 Postmortem을 작성.
2. Chaos Engineering (혼란 공학)
- 장애가 발생하기 전에 의도적으로 시스템에 혼란을 가해 취약점을 찾아내는 방법론.
- 목적: 장애 발생 시 실제로 시스템이 어떻게 반응하는지 사전에 테스트.
- 도구: Chaos Monkey, Gremlin.
활용 사례: Netflix는 Chaos Engineering을 통해 대규모 트래픽에도 시스템이 안정적으로 동작하도록 설계.
3. 장애에 강한 시스템 설계 원칙
- 불변성 인프라
- 서버의 상태를 유지하지 않고, 문제가 발생하면 새로운 인스턴스를 생성.
- 예: AWS EC2 Auto Scaling, Immutable AMI.
- 백프레셔 (Backpressure)
- 시스템 과부하 시 요청을 제한하여 전체 시스템의 장애를 방지.
- 예: 스프링 WebFlux의 리액티브 스트림을 사용한 비동기 처리.
- Retry와 Timeout
- 장애가 발생했을 때 요청을 재시도하되, 무한 재시도를 방지하기 위한 Timeout 설정.
- 예: Resilience4j 라이브러리를 사용해 재시도와 Circuit Breaker 구현.
4. 로그 관리 및 분석
- 로그는 장애 원인 분석에 중요한 데이터.
- Best Practice:
- 로그 수준 정의: ERROR, WARN, INFO, DEBUG.
- 중앙 집중형 로그 관리 도입: ELK Stack, Splunk.
- 로그 예시:
log.error("Database connection failed: {}", exception.getMessage());
- Best Practice:
기술적인 도구 활용
1. 모니터링 도구
- 애플리케이션 성능 모니터링(APM): New Relic, AppDynamics, Datadog.
- 분산 트레이싱: Zipkin, Jaeger.
2. 배포 전략 도구
- Blue-Green Deployment: 프로덕션 환경에서 장애를 최소화.
- Canary Deployment: 소수의 사용자에게 먼저 변경사항을 적용.
3. 자동화 도구
- CI/CD 파이프라인: Jenkins, GitHub Actions.
- 인프라 관리: Terraform, Ansible.
장애 대응 문화와 사고방식
1. Blameless Culture (책임 추궁 없는 문화)
- 장애가 발생했을 때 개인을 비난하지 않고, 시스템의 개선점을 찾는 데 집중.
- 장애는 개인의 실수가 아닌 시스템 설계의 문제로 간주.
2. 지속적 개선 (Continuous Improvement)
- 장애 대응 후 반드시 예방 조치와 개선 작업을 실행.
3. 실패 수용 (Fail-Friendly Mindset)
- "언제든 장애는 발생할 수 있다"는 가정을 기반으로 대응 계획을 수립.
정리
- 애플리케이션(시스템)을 운영하는데 있어서 중요한 것 중 하나인 장애 대응에 대해 배워 보았다.
- 장애 대응에 필요한 사항과 사고방식에 대해 알게 되었으며, 추후 프로젝트를 진행할 때 배운 내용을 적용해 보면 좋을 것 같다.
'자바 심화 > TIL' 카테고리의 다른 글
| Redis - Redisson (2) | 2024.12.27 |
|---|---|
| DB Lock (1) | 2024.12.26 |
| 시큐어 코딩(Secure Coding) (0) | 2024.12.23 |
| 모니터링 - Slack Alert 보내기 (1) | 2024.12.20 |
| 모니터링(Monitoring) (1) | 2024.12.19 |


