정렬 알고리즘(Sort Algorithm)
원소들을 일정한 순서대로 열거하는 알고리즘
정렬 알고리즘을 사용할 때, 상황에 맞게 다음의 기준들로 사용할 알고리즘을 선정한다.
- 시간 복잡도 (소요되는 시간)
- 공간 복잡도 (메모리 사용량)
시간, 공간 복잡도는 Big-O 표기법으로 나타낼 수 있다.
정렬되는 항목 외에 충분히 무시할 만한 저장공간만을 더 사용하는 정렬 알고리즘들을 제자리 정렬이라고 한다.
정렬 알고리즘의 특징
| 특징 | 설명 |
| 시간 복잡도 | 일부 알고리즘은 작은 데이터 집합에 대해 빠르지만, 큰 데이터 집합에 대해 느릴 수 있다. 알고리즘의 시간 복잡도를 고려하여 적절한 정렬 알고리즘을 선택해야 한다. |
| 안정성 | 안정적인 정렬 알고리즘은 동일한 값의 순서가 바뀌지 않는 특징을 가지고 있다. 이는 동일한 값을 가진 요소들의 순서가 변하지 않도록 보장된다. |
| 추가 메모리 사용 | 몇몇 정렬 알고리즘은 추가적인 메모리 공간을 필요로 한다. 정렬 알고리즘을 선택할 때 고려해야 할 요소 중 하나로 메모리 효율적인 알고리즘을 선호해야 한다. |
| 알고리즘의 복잡성 | 정렬 알고리즘의 복잡성은 알고리즘의 이해와 구현의 어려움을 의미한다. 몇몇 알고리즘은 간단하고 이해하기 쉽지만, 다른 알고리즘은 복잡하고 이해하기 어렵다. |
순서가 바뀌지 않는다
- 동일한 값을 가진 요소들의 순서가 정렬 전후로 변하지 않는 특징을 가지는 것을 의미한다.
- 만약 동일한 값을 가진 두 요소가 정렬되기 전에는 첫 번째 요소가 두 번째 요소보다 앞에 위치하고, 정렬된 후에도 첫 번째 요소가 두 번째 요소보다 앞에 위치하게 된다.
- 정렬 알고리즘이 동일한 값의 순서를 보존한다는 것을 의미한다.
시간 복잡도
- 알고리즘이 실행될 때 필요한 '입력 값'과 '연산 수행 시간'에 따라 효율적인 알고리즘을 나타내는 척도를 의미한다.
- 입력 값이 커질수록 알고리즘의 수행 시간이 어떻게 증가하는지에 다른 지표로 시간 복잡도는 '빅오 표기법(Big-O notation)'를 통해 표현하며 수치가 작을수록 효율적인 알고리즘을 의미한다.
정렬 알고리즘 종류
정렬 알고리즘 종류 요약

| 알고리즘 종류 | 설명 |
| 퀵 정렬(Quick Sort) | 분할 정복 방식을 이용하여 배열을 빠르게 정렬하는 알고리즘 |
| Arrays.sort() | 퀵 정렬을 사용하여 배열을 정렬하는데 사용되며 기본 타입 배열과 객체 타입 배열 모두에 대해 사용할 수 있다. |
| Collections.sort() | 퀵 정렬을 사용하여 객체를 정렬하는데 사용되며 List, Set, Queue 등의 컬렉션 프레임워크에 대해 사용할 수 있다. |
| 버블 정렬(Bubble Sort) | 인접한 두 원소를 비교하여 큰 값을 오른쪽으로 이동시키는 방식으로 정렬하는 알고리즘이다. |
| 선택 정렬(Selection Sort) | 주어진 배열에서 최소값을 찾아 맨 앞 원소와 교환하는 방식으로 정렬하는 알고리즘이다. |
| 삽입 정렬(Insertion Sort) | 정렬되어 있는 부분 집합 내에서 자신이 들어갈 위치를 찾아 삽입하는 방식으로 정렬하는 알고리즘이다. |
| 병합 정렬(Merge Sort) | 분할 정복 방식을 이용하여 배열을 정렬하는 알고리즘이다. |
| 힙 정렬(Heap Sort) | 힙이라는 자료구조를 이용하여 정렬하는 알고리즘이다. |
| 기수 정렬(Radix Sort) | 각 자리의 숫자를 비교하여 정렬하는 알고리즘이다. |
정렬 알고리즘의 종류별 시간 복잡도
정렬 알고리즘의 종류별 시간복잡도와 최악 시간복잡도이다.
| 알고리즘 종류 | 평균 시간 복잡도 | 최악 시간 복잡도 |
| 퀵 정렬(Quick Sort) | O(nlogn) | O(n^2) |
| 퀵 정렬: Arrays.sort() | O(nlogn) | O(n^2) |
| 퀵 정렬: Collections.sort() | O(nlogn) | O(n^2) |
| 버블 정렬(Bubble Sort) | O(n^2) | O(n^2) |
| 선택 정렬(Selection Sort) | O(n^2) | O(n^2) |
| 삽입 정렬(Insertion Sort) | O(n^2) | O(n^2) |
| 병합 정렬(Merge Sort) | O(nlogn) | O(nlogn) |
| 힙 정렬(Heap Sort) | O(nlogn) | O(nlogn) |
| 기수 정렬(Radix Sort) | O(d(n + k)) | O(d(n + k)) |
시간 복잡도를 기준으로 순서대로 속도가 빠르다.
퀵 정렬 > 퀵 정렬 : Arrays.sort() > 퀵 정렬 : Collections.sort() > 버블 정렬 > 선택 정렬 > 삽입 정렬 > 병합 정렬 > 힙 정렬 > 기수 정렬

퀵 정렬(Quick Sort)
- 분할 정복(Divide and Conquer) 방법을 사용하여 구현된 정렬 알고리즘을 의미한다.
- 대규모 데이터를 정렬하는 데 매우 유용하며, 많은 프로그래밍 언어에서도 내장된 정렬 함수에 사용되는 알고리즘
분할 정복(Divide and Conquer)
- 큰 문제를 작은 문제로 나눠서 해결하는 알고리즘을 의미, 분할 → 정복 → 결합의 단계 처리가 된다.
- 분할 단계는 문제를 작은 부분 문제들로 나누는 단계
- 정복 단계는 부분 문제를 해결하는 단계
- 결합 단계는 부분 문제의 해들을 모아 원래의 해를 구하는 방식을 의미

동작 방식
퀵 정렬의 동작 방식
- 배열에서 하나의 요소를 기준으로 선택한다. 이를 피벗(Pivot)이라고 한다.
- 피벗을 기준으로 작은 요소는 피벗의 왼쪽으로, 큰 요소는 피벗의 오른쪽으로 분할한다.
- 분할된 두 개의 하위 배열에 대해 재귀적으로 위의 과정을 반복한다.
- 하위 배열이 더 이상 분할되지 않으면 정렬이 완료된다.
퀵 정렬에서 분할 정복 방법을 사용하여 구현되었기 때문에, 배열을 분할하고 분할된 부분 배열에 대해 재귀적으로 정렬을 수행하는 방식으로 동작한다.
이런 분할 정복의 개념을 통해 퀵 정렬이 효과적으로 동작하고 배열을 정렬할 수 있다.

퀵 정렬 종류 : 일반 정렬 알고리즘(Arrays.sort(), Collections.sort())
- Arrays.sort()
- 퀵 정렬을 사용하여 배열을 정렬하는 데 사용되며 기본 타입 배열과 객체 타입 배열 모두에 대해 사용할 수 있다.
- Collections.sort()
- 퀵 정렬을 사용하여 객체를 정렬하는데 사용되며 List, Set, Queue 등의 컬렉션 프레임워크에 대해 사용할 수 있다.
버블 정렬(Bubble Sort)
- 인접한 두 원소를 비교하여 필요한 경우 위치를 교환하여 배열을 정렬하는 방식을 의미한다.
- 해당 정렬 방식은 정렬할 원소의 개수가 적을 때나, 정렬할 원소의 개수가 많더라도 이미 거의 정렬된 상태일 때 사용될 수 있다.
- 대부분의 경우 다른 정렬 알고리즘들보다 느리고 비효율적이기 때문에, 실제로 사용되는 경우는 드물다.
동작 방식
- 배열의 첫 번째 요소부터 인접한 요소와 비교한다.
- 만약 인접한 요소의 순서가 잘못되어 있다면 위치를 교환한다.
- 배열의 끝까지 이동하면서 위의 과정을 반복한다.
- 한 번의 반복이 끝나면 가장 큰 요소가 배열의 마지막으로 이동한다.
- 위 과정을 배열이 정렬될 때까지 반복한다.

선택 정렬(Selection Sort)
- 주어진 배열에서 최소값을 찾아서 맨 앞의 원소와 자리를 바꾸고 그 다음으로 작은 값을 찾아서 두 번째 원소와 자리를 바꾸는 식으로 정렬하는 알고리즘 중 하나
- 정렬할 원소의 개수가 적을 때난 이미 거의 정렬된 상태일 때 사용될 수 있다.
- 대부분의 경우 다른 정렬 알고리즘들보다 느리고 비효율적이기 때문에, 실제로 사용되는 경우는 드물다.
동작 방식
- 배열에서 가장 작은 요소(최소값)를 찾는다.
- 가장 작은 요소와 배열의 첫 번재 요소를 교환한다.
- 두 번째로 작은 요소를 찾아 두 번째 요소와 교환한다.
- 이러한 과정을 배열의 끝까지 반복한다.
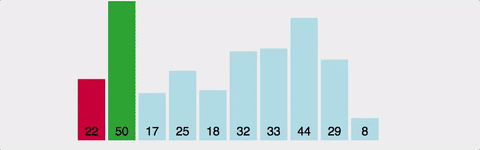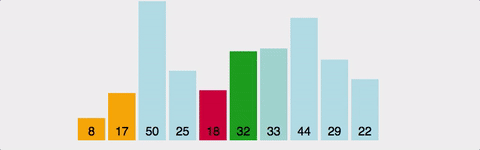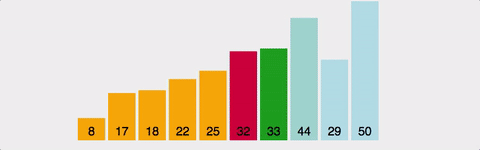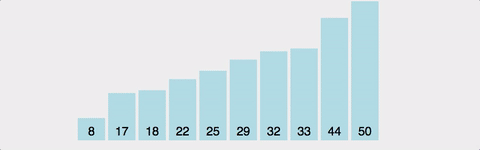
삽입 정렬(Insertion Sort)
- 정렬되지 않은 부분에서 값을 선택하고 그 값을 이미 정렬된 부분의 올바른 위치에 삽입하는 과정을 수행하는 알고리즘
- 이를 통해 정렬되지 않은 부분은 점차적으로 감소하고 전체 배열이 정렬되게 된다.
동작 방식
- 배열의 두 번째 요소부터 시작한다.
- 현재 위치의 요소를 기준으로, 이전 위치의 요소들과 비교한다.
- 이전 위치의 요소가 현재 위치의 요소보다 크다면, 이전 위치의 요소를 현재 위치로 이동시킨다.
- 이전 위치의 요소가 현재 위치의 요소보다 작거나 같다면, 정렬이 완료된 것으로 간주하고 다음 요소로 이동한다.
- 배열의 시작에 도달할 때까지 반복한다.

병합 정렬(Merge Sort)
- 배열을 반으로 나누어 각각을 정렬한 후, 병합하는 과정을 통해 전체 배열을 정렬한다.
- 배열을 반으로 나눠 각각을 재귀적으로 정렬하고 정렬된 두 개의 배열을 병합하는 단계에서 작은 값을 선택해 새로운 배열에 차례대로 배치한다.
- 이 과정을 반복하면서 전체 배열이 정렬되게 된다.
동작 방식
- 배열을 반으로 나눈다.
- 각 반쪽을 재귀적으로 정렬한다.
- 정렬된 두 개의 반쪽을 병합하여 하나의 정렬된 배열로 합친다.

힙 정렬(Heap Sort)
- 주어진 배열을 힙으로 만들고, 가장 큰 값을 배열의 가장 마지막으로 보내는 방식으로 정렬을 진행한다.
- 안정적인 정렬 알고리즘이며, 평균적으로 다른 정렬 알고리즘에 비해 빠른 실행 시간을 가지는 특징이 있다.
- 추가적인 메모리 공간이 필요하다는 단점이 있다.
동작 방식
- 주어진 배열을 최대 힙(Max Heap)으로 구성한다.
- 최대 힙에서 가장 큰 요소(루트)를 가져와 배열의 맨 끝으로 이동시킨다.
- 배열의 크기를 줄이고, 남은 요소들을 다시 최대 힙으로 구성한다.
- 위의 과정을 반복하여 정렬이 완료될 때까지 진행한다.
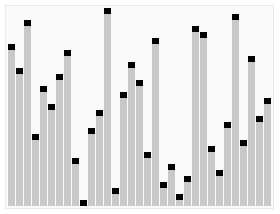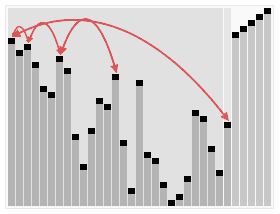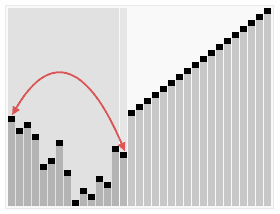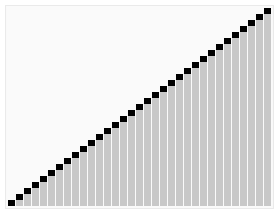
완전 이진트리를 사용한다.
기수 정렬(Radix Sort)
- 비교 연산을 사용하지 않고, 자릿수별로 정렬을 수행하는 알고리즘
- 정렬할 숫자들을 가장 낮은 자릿수부터 가장 높은 자릿수까지 반복적으로 처리한다.
- 각 자릿수별로 숫자를 그룹으로 나누고, 해당 그룹 내에서 정렬을 수행한다.
- 이 과정을 가장 높은 자릿수까지 반복하면 전체 숫자들이 정렬되게 된다.
동작 방식
- 정렬할 요소들을 가장 낮은 자릿수부터 가장 높은 자릿수까지 반복적으로 정렬한다.
- 각 자릿수에 대해 요소들을 해당 자릿수의 값에 따라 그룹화한다.
- 그룹화된 요소들을 순서대로 다시 배열한다.
- 위의 과정을 가장 높은 자릿수까지 반복하여 정렬이 완료될 때까지 진행한다.

'항해 99 > Java' 카테고리의 다른 글
| Java - 불변 객체 (0) | 2024.05.31 |
|---|---|
| Java - Object (0) | 2024.05.29 |
| Array & LinkedList (0) | 2024.05.03 |
| Java - Garbage Collector, Java Map (1) | 2024.04.08 |
| Java - 컴파일, JVM 스택 / 힙 메모리, 클래스 / 인스턴스 (0) | 2024.04.05 |



